
Understanding the Heap Internals
So far in this series, we've exploited the stack buffer overflows, ROP chains, format strings. The stack is predictable: local variables go in, function returns pop them out, everything follows a strict LIFO order.
The heap is a completely different beast. It's dynamic memory malloc() and free(). Programs request memory of arbitrary sizes at arbitrary times and free it in any order. The heap allocator has to manage this chaos efficiently, and the bookkeeping metadata it uses to track allocations is exactly what attackers target.
Heap exploitation is how most modern exploits work. Browser exploits, kernel exploits, server exploits the majority involve heap corruption. The stack is too well-protected (canaries, ASLR, DEP). The heap is where the action is.
But before we can exploit the heap, we need to understand how it works. This article covers the internals of glibc's malloc (ptmalloc2) the default allocator on Linux. The next article covers the actual exploitation techniques.
I know. This going to be a very lengthy article, BTW I did not want to split this into multiple posts. Here you can find the whole complete idea about the heap you need for the Heap based buffer overflows.
Stack vs Heap — The Fundamental Difference
Stack:.
- Fixed size (usually 8MB per thread)
- Grows/shrinks automatically with function calls
- LIFO order — last allocated, first freed
- Managed by the compiler (push/pop)
- Local variables, function arguments, return addresses
Heap:
- Dynamic size (grows as needed)
- Allocated/freed explicitly by the programmer
- No ordering — free in any order
- Managed by the allocator (malloc/free)
- Dynamically sized data, objects, buffers
To understand the differences lets consider a simple C function.
void memoryAllocation() {
int x = 42; // Stack — automatic, freed when function returns
char *buf = malloc(256); // Heap — manual, stays until free() is called
free(buf); // Programmer must free explicitly
}The stack is simple. The heap is complex. And complexity breeds vulnerabilities.
malloc() and free() — The Interface
The programmer sees a simple API:
void *malloc(size_t size); // Allocate 'size' bytes, return pointer
void free(void *ptr); // Free previously allocated memory
void *realloc(void *ptr, size_t size); // Resize allocation
void *calloc(size_t nmemb, size_t size); // Allocate and zero-initializeBehind this simple interface, glibc's malloc maintains a sophisticated system of chunks, bins, and arenas to manage memory efficiently.
Chunks — The Building Block
The first and most important concept in this tutorial is the chunk. As the first step we are going to see what is a chunk and how it looks like.
Every malloc() allocation is wrapped in a chunk.
Each chunk contains metadata (header) and the user data.
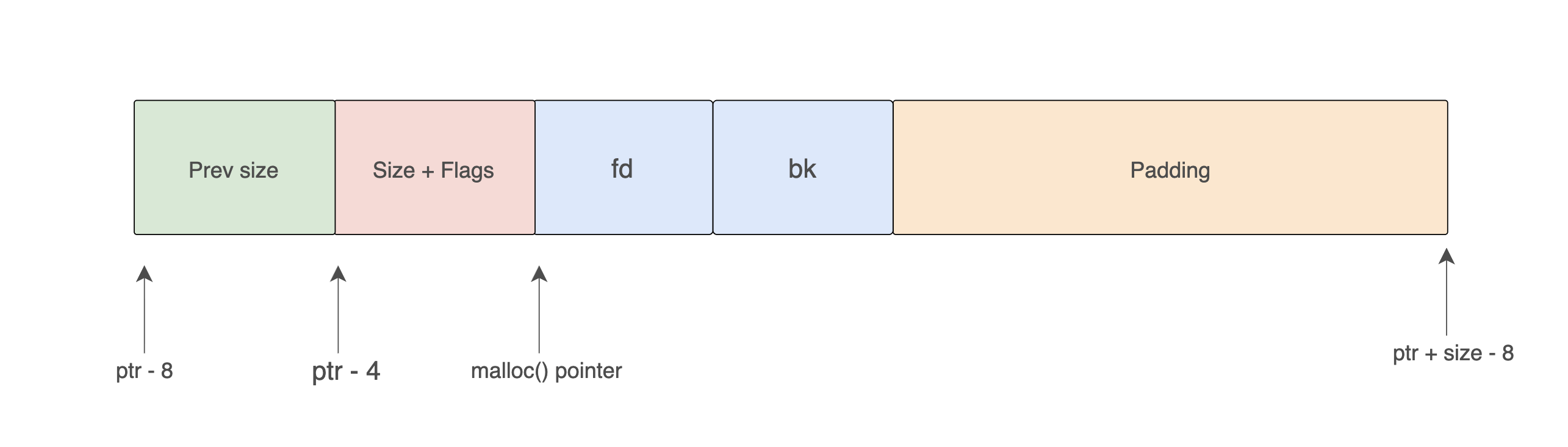
Allocated Chunk Layout
The actual layout of a chunk is something like below.

We know that whenever we use malloc() function we recieve a pointer. (If memory allocation was success). This pointer is always pointed to the user data. Not to the starting of the chunk. In the 32 bit architecture the meta data is 8 bytes in size. So, if we want to get the address of the starting point of the chunk we have do substract 8 from the pointer which is returned by malloc(). We need to keep this in mind.
Now lets dive deep in to the chunk and see how it looks like.

The meta data section has two parts,
Prev size
This indicates the size of the previous chunk. Actually this does not represent the size always. I'll explain it later. For now keep in mind this represents the size of the previous chunk.
prev_size stores the size of the previous chunk in memory — but only when that previous chunk is free. When the previous chunk is allocated, this 4-byte field is recycled as extra user data by the previous chunk (the prev_size overlap optimization). This is not a bug — it is intentional and documented in the allocator source. The PREV_INUSE flag in the current chunk's size field is the authoritative signal for whether prev_size is valid metadata or live user data. Off-by-one heap overflows are dangerous precisely because corrupting the prev_size of the next chunk can cause the allocator to miscompute chunk boundaries during consolidation.
Size + Flags
As the name suggests, this indicates the size field stores the chunk's total size, but the bottom 3 bits are repurposed as flags.
Wait. How that is possible? Let me explain.
The chunk size is always a multiplication of 8. Such as 8 bytes, 16 bytes, 24 bytes etc.
$$ 8_{10} = 00001000_2 $$
$$ 16_{10} = 00010000_2 $$
$$ 24_{10} = 00011000_2 $$
$$ 32_{10} = 00100000_2 $$
So the last 3 bits of the size would always be zero. We can use these three bits as the space for the flags.
Actual Size in bytes + | A | M | P || Bit | Name | Meaning |
|---|---|---|
| Bit 0 | P (PREV_INUSE) | Previous chunk is in use (not free) |
| Bit 1 | M (IS_MMAPPED) | Chunk was allocated via mmap() |
| Bit 2 | A (NON_MAIN_ARENA) | Chunk belongs to a non-main arena (threading) |
The PREV_INUSE bit is critical for exploitation. It tells the allocator whether the chunk before this one is free.
Lets consider an example, We see following as the metadata for the current chunk.
size + flags = 0x00000021Now,
$$ 00000021_{16} = 33_{10} $$
So this does not mean the actual size is 33 bytes.
To get the actual size, we need to convert it into binary and disregard the last three bits,
$$ 33_{10} = 0100001_2 $$
After removing the last three digits it is 0100000.
$$ 0100000_2 = 32_{10} $$
In a programmatically we can say this in below way,
We can use the bitwise AND operator with 11111000 to get rid of the last three bits.
$$ 0100001_{2} \land 11111000_{2} $$
Size of allocation
#define request2size(req)
(((req) + SIZE_SZ + MALLOC_ALIGN_MASK < MINSIZE) ?
MINSIZE :
((req) + SIZE_SZ + MALLOC_ALIGN_MASK) & ~MALLOC_ALIGN_MASK)- MALLOC_ALIGNMENT 15 bytes
- SIZE_SZ 4 bytes (sizeof(size_t) on 32-bit)
- MALLOC_ALIGN_MASK 15 bytes (MALLOC_ALIGNMENT - 1)
- MINSIZE 16 bytes
Now, it's time to see an example.
We are going to allocate a chunk with the size 14 bytes. So, we call malloc(14). Let say this is chunk A.
size = (14 + 4 + 15 < 16) ? 16 : (14 + 4 + 15) & ~15)
= 33 & ~1515 = 0000 0000 0000 0000 0000 0000 0000 1111
~15 = 1111 1111 1111 1111 1111 1111 1111 000033 = 0000 0000 0000 0000 0000 0000 0010 0001
~15 = 1111 1111 1111 1111 1111 1111 1111 0000
33 & ~15 = 0000 0000 0000 0000 0000 0000 0010 0000So the allocated size for the chunk is 32. User data size is
$$ \text{32 - 4 x 2 = 24 bytes} $$
$$ \text{Padding = 24 - 14 = 8 bytes} $$
So, current chunk's size should be 0x00011000.
But, we store the flags with the current chunk's size.
| Chunk | Prev Size | Size & Flags | len(Userdata) | len(Padding) |
|---|---|---|---|---|
| Chunk A | 0x00000000 | 00100001 | 24 Bytes | 8 Bytes |
Next, we are going to allocate a chunk with the size 12 bytes. Let say this is chunk B.
size = (12 + 4 + 15 < 16) ? 16 : (12 + 4 + 15) & ~15)
= 31 & ~1531 = 0000 0000 0000 0000 0000 0000 0001 1111
~15 = 1111 1111 1111 1111 1111 1111 1111 0000
31 & ~15 = 0000 0000 0000 0000 0000 0000 0001 0000So the allocated size for the chunk is 16.
$$ \text{user data = 16 - 4 x 2 = 8 bytes} $$
Wait, We requested 12 bytes but it gave only 8 bytes. Then how we can store some data? The answer is borrowing. We need to borrow some small space (4 bytes in this case) from the next chunk.
Again another question. Will the next chunk provide some space for us? Does next chunk have free space always?
So, current chunk's size should be 0x00000010.
But, we store the flags with the current chunk's size.
| Chunk | Prev Size | Size & Flags | len(Userdata) | len(Padding) |
|---|---|---|---|---|
| Chunk B | 0x00000000 | 00010001 | 8 Bytes | 0 Bytes |
Lets see one another example, I took several diferent cases so we can clearly see this. This time we are requesting 20 bytes.
size = (20 + 4 + 15 < 16) ? 16 : (20 + 4 + 15) & ~15)
= 39 & ~1539 = 0000 0000 0000 0000 0000 0000 0010 0111
~15 = 1111 1111 1111 1111 1111 1111 1111 0000
39 & ~15 = 0000 0000 0000 0000 0000 0000 0010 0000So the allocated size for the chunk is 32 Bytes.
$$ \text{user data = 32 - 4 x 2 = 24 bytes} $$
| Chunk | Prev Size | Size & Flags | len(Userdata) | len(Padding) |
|---|---|---|---|---|
| Chunk C | 0x00000000 | 00100001 | 24 Bytes | 4 Bytes |
Finally I'm going to request 40 bytes. I took several different cases so we can clearly see this.
size = (40 + 4 + 15 < 16) ? 16 : (40 + 4 + 15) & ~15)
= 59 & ~1559 = 0000 0000 0000 0000 0000 0000 0011 1011
~15 = 1111 1111 1111 1111 1111 1111 1111 0000
39 & ~15 = 0000 0000 0000 0000 0000 0000 0011 0000So the allocated size for the chunk is 48 Bytes.
$$ \text{user data = 48 - 4 x 2 = 40 bytes} $$
| Chunk | Prev Size | Size & Flags | len(Userdata) | len(Padding) |
|---|---|---|---|---|
| Chunk D | 0x00000000 | 0x00000041 | 40 Bytes | 0 Bytes |
Now we know how the malloc() works and how does it allocate some memory for us. Now things are getting more interesting. We need to learn what happens when we call free(). How does the memory area get freed? There are two important points we need to learn. Bins and Tcache. More specifically we can say these are the key points we need.
- unsorted / small / large bins
- fastbins
- tcache (modern glibc, default)
Bins — Where Free Chunks Live
When you call free(), the memory doesn't go back to the operating system immediately. Instead, glibc keeps it in a bin which is a free list it drains before ever asking the kernel for more memory. This makes repeated malloc()/free() cycles fast: the allocator reuses cached chunks instead of calling sbrk() every time.
There are four types of bins.
- Fast bins
- Unsorted bins
- Small bins
- Large bins
Each bin type handles a different chunk size range. Here is the full picture before we dive into each one:
| Chunk size range | Goes to on free() |
Eventually sorted to |
|---|---|---|
0x10 – 0x40 |
fastbin | (stays in fastbin) |
0x50 – 0x3f0 |
unsorted bin | smallbin |
0x400+ |
unsorted bin | largebin |
Two things are worth noting from this table before we go further.
First, chunks in the 0x10–0x40 range go directly to fastbins and never touch the unsorted bin at all. They skip coalescing, skip the doubly-linked list machinery, and get reused with minimal overhead. I know some of these terms are new to you. Don't worry I'll explain each and every term clearly in next paragraphs.
Second, no chunk ever goes directly into a smallbin or largebin on free(). Every non-fastbin chunk always lands in the unsorted bin first. It only gets sorted into its proper smallbin or largebin slot the next time malloc() walks the unsorted bin looking for a chunk of a different size. This lazy sorting is a deliberate design choice — it keeps free() fast by deferring the sorting work to the next allocation.
Actually, this fastbin concept is a new feature introduced in newer kernel versions.
Now, it's the time to understand each of these seperetly and deeply.
Fast Bins
A fast bin is made of a linked list. More specifically a singly linked list. That means the fast bin section is a collection of linked lists.
Yes, finally an actual usage of Linked lists :).
For the chunks which have the size 0x10, there is a separate linked list (Fast bin). Similarly, for the chunks which have the size 0x20, there is another linked list.
With MALLOC_ALIGNMENT = 16 (glibc ≥ 2.26, 32-bit), valid fastbin chunk sizes are multiples of 16:
0x10, 0x20, 0x30, 0x40The bin index for a given chunk size is:
cfastbin_index(sz) = (sz >> 3) - 2| Chunk size | Calculation | Index |
|---|---|---|
0x10 (16 bytes) |
(0x10 >> 3) - 2 = 2 - 2 | fastbinsY[0] |
0x20 (32 bytes) |
(0x20 >> 3) - 2 = 4 - 2 | fastbinsY[2] |
0x30 (48 bytes) |
(0x30 >> 3) - 2 = 6 - 2 | fastbinsY[4] |
0x40 (64 bytes) |
(0x40 >> 3) - 2 = 8 - 2 | fastbinsY[6] |
Indices 1, 3, 5, 7 remain empty because no chunk sizes map to them with 16-byte alignment.
And one another important thing is fastbins are LIFO. That means last freed, first allocated.
The layout of a chunk after it is moved into a fast bin is below.

As I mentioned there is a one pointer called fd. And it is placed at the user data section. Since the userdata section is not intended to be used after free() call, that region is repurposed by the allocator to store the fd pointer.
So, what does this fd pointer do? lets see.
To understand the concepts, we are going to use the following examples.
| Chunk | Prev Size | Size & Flags | User Data Capacity | fastbinsY index |
|---|---|---|---|---|
| Chunk A | 0x00000000 |
0x00000021 |
24 bytes | 2 |
| Chunk B | 0x00000000 |
0x00000011 |
8 bytes | 0 |
| Chunk C | 0x00000000 |
0x00000021 |
24 bytes | 2 |
| Chunk D | 0x00000000 |
0x00000041 |
56 bytes | 6 |
| Chunk E | 0x00000000 |
0x00000021 |
24 bytes | 2 |
| Chunk F | 0x00000000 |
0x00000021 |
24 bytes | 2 |
Quick size extraction for each:
Chunk A, C, E, F: 0x21 & ~0xF = 0x20 = 32 bytes → fastbinsY[2]
Chunk B: 0x11 & ~0xF = 0x10 = 16 bytes → fastbinsY[0]
Chunk D: 0x41 & ~0xF = 0x40 = 64 bytes → fastbinsY[6]You may wondering why the Prev Size is empty in each. This is because Prev Size is useful only after these chunks are free. Wheen these are in use there is no point of keeping the prev size data.
Now, let's say these are in memory at the following addresses. The chunk starts 8 bytes before the user pointer:
| Chunk | Chunk Address | User Pointer |
|---|---|---|
| Chunk A | 0x5655a1a0 |
0x5655a1a8 |
| Chunk B | 0x5655a1c0 |
0x5655a1c8 |
| Chunk C | 0x5655a1d0 |
0x5655a1d8 |
| Chunk D | 0x5655a1f0 |
0x5655a1f8 |
| Chunk E | 0x5655a230 |
0x5655a238 |
| Chunk F | 0x5655a250 |
0x5655a258 |
Initial state — all allocated, all bins empty:
fastbinsY[0]: NULL
fastbinsY[2]: NULL
fastbinsY[6]: NULLStep 1 — free(A)
Since the size of the chunk is 32 bytes, it should go to the fastbin which is the index is 2 (fastbinsY[2]).
fastbinsY[2] is currently NULL. The allocator writes fd = NULL into A's user data region and updates fastbinsY[2] to point to A's chunk.
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 |
0x00000021 |
0x00000000 |
Memory at 0x5655a1a0 (A's chunk): 0x5655a1a0: 0x00000000 0x00000021 0x00000000 prev_size size|flags fd = NULL
fastbinsY[0]: NULL
fastbinsY[2]: 0x5655a1a0 → NULL
fastbinsY[6]: NULLStep 2 — free(C)
The chunk C's size is also 32 bytes, it should go to the fastbin which is the index is 2 (fastbinsY[2]).
fastbinsY[2] currently points to A (0x5655a1a0). The allocator writes the current head into C's fd, then sets fastbinsY[2] to C.
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 |
0x00000021 |
0x00000000 |
| Chunk C | 0x00000000 |
0x00000021 |
0x5655a1a0 |
fastbinsY[0]: NULL
fastbinsY[2]: 0x5655a1d0 → 0x5655a1a0 → NULL
fastbinsY[6]: NULLStep 3 — free(E)
Same process. E's fd gets C's address.
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 | 0x00000021 | 0x00000000 |
| Chunk C | 0x00000000 | 0x00000021 | 0x5655a1a0 |
| Chunk E | 0x00000000 | 0x00000021 | 0x5655a1d0 |
fastbinsY[2]: 0x5655a230 → 0x5655a1d0 → 0x5655a1a0 → NULLStep 4 — free(B)
Since the size of the chunk is 16 bytes, it should go to the fastbin which is the index is 1 (fastbinsY[1]). It is a completely separate list.
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 | 0x00000021 | 0x00000000 |
| Chunk C | 0x00000000 | 0x00000021 | 0x5655a1a0 |
| Chunk E | 0x00000000 | 0x00000021 | 0x5655a1d0 |
| Chunk B | 0x00000000 | 0x00000011 | 0x00000000 |
fastbinsY[0]: 0x5655a1c0 → NULL
fastbinsY[2]: 0x5655a230 → 0x5655a1d0 → 0x5655a1a0 → NULL
fastbinsY[6]: NULLStep 5 — free(D)
D is 0x40 bytes → fastbinsY[6].
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 | 0x00000021 | 0x00000000 |
| Chunk C | 0x00000000 | 0x00000021 | 0x5655a1a0 |
| Chunk E | 0x00000000 | 0x00000021 | 0x5655a1d0 |
| Chunk B | 0x00000000 | 0x00000011 | 0x00000000 |
| Chunk D | 0x00000000 | 0x00000041 | 0x00000000 |
fastbinsY[0]: 0x5655a1c0 → NULL
fastbinsY[2]: 0x5655a230 → 0x5655a1d0 → 0x5655a1a0 → NULL
fastbinsY[6]: 0x5655a1f0 → NULLStep 6 — free(F)
F is 0x20 bytes → fastbinsY[2]. F becomes the new head, its fd gets E's address.
| Chunk | Prev Size | Size & Flags | fd |
|---|---|---|---|
| Chunk A | 0x00000000 | 0x00000021 | 0x00000000 |
| Chunk C | 0x00000000 | 0x00000021 | 0x5655a1a0 |
| Chunk E | 0x00000000 | 0x00000021 | 0x5655a1d0 |
| Chunk B | 0x00000000 | 0x00000011 | 0x00000000 |
| Chunk D | 0x00000000 | 0x00000041 | 0x00000000 |
| Chunk F | 0x00000000 | 0x00000021 | 0x5655a230 |
fastbinsY[0]: 0x5655a1c0 → NULL
fastbinsY[2]: 0x5655a250 → 0x5655a230 → 0x5655a1d0 → 0x5655a1a0 → NULL
fastbinsY[6]: 0x5655a1f0 → NULLNow we have above state. We need to see what happens when we are going to re allocate a memory.
malloc() — LIFO Drain
Now call malloc(24). The allocator computes the chunk size:
(24 + 4 + 15) & ~15 = 43 & ~15 = 32 = 0x20 → fastbinsY[2]It pops the head of fastbinsY[2] — which is F — and updates the bin head to F's fd (= E's address). Returns 0x5655a258 (F's user pointer = F's chunk address + 8).
fastbinsY[0]: 0x5655a1c0 → NULL
fastbinsY[2]: 0x5655a230 → 0x5655a1d0 → 0x5655a1a0 → NULL
fastbinsY[6]: 0x5655a1f0 → NULLmalloc(24) call 1 → 0x5655a258 (F returned) fastbinsY[2]: E → C → A
malloc(24) call 2 → 0x5655a238 (E returned) fastbinsY[2]: C → A
malloc(24) call 3 → 0x5655a1d8 (C returned) fastbinsY[2]: A
malloc(24) call 4 → 0x5655a1a8 (A returned) fastbinsY[2]: NULLFree order was: A → C → E → F
Return order is: F → E → C → A
LIFO confirmed.
How malloc serves a fast bin request
When malloc(n) is called and n falls within fast bin range, glibc computes the bin index:
fastbin_index = (size >> 3) - 2 // 0x10 → index 0, 0x20 → index 2, …It reads the head pointer from fastbinsY[index], pops that chunk off the list (updating the head to point to fd), and returns a pointer to the user data. If the bin is empty, glibc falls through to the unsorted bin path.
When the fast bins eventually need to be drained (for example, during a malloc_consolidate() call triggered by a large allocation), all fast bin chunks are coalesced with their neighbors and dumped into the unsorted bin for proper sorting.
Key properties:
- No coalescing : adjacent free chunks in fast bins are NOT merged together
- LIFO order : free(a); free(b); malloc(same_size) returns b (last freed, first out)
- Singly linked : only
fd, nobk - PREV_INUSE bit is not cleared : the next chunk doesn't know this chunk is free
Fast bins exist for performance. Small, frequent allocations (the most common case) are served extremely quickly.
Unsorted Bin
When a non-fastbin chunk is freed, it first goes into the unsorted bin. This is a single doubly-linked list that acts as a staging area.
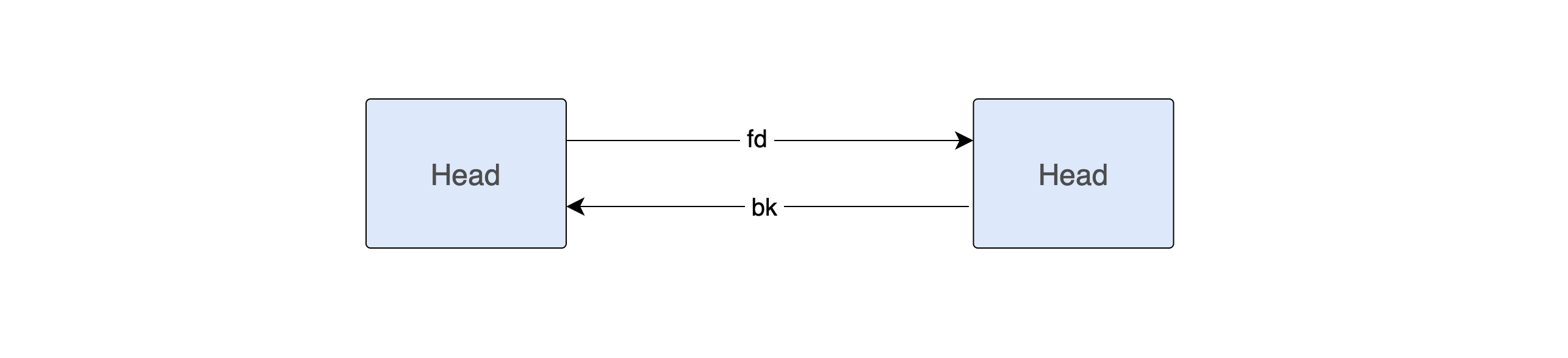
When a chunk is freed, the user data area is repurposed to store free list pointers:
The fd and bk pointers form a doubly-linked list of free chunks. This is where the allocator finds memory to satisfy future malloc() calls.
These pointers occupy the same memory that was previously user data. The allocator knows it's safe to write here because the chunk is free and nobody should be reading this memory anymore.
The unsorted bin is stored at index 1 of the arena's bins[] array, and like all bin lists it is circular: the last chunk's fd and the first chunk's bk both point back to the bin head
Forsdf the unsorted bin we need chunks that are above the fastbin range (size > 0x40). Let us allocate four large chunks:
| Chunk | Prev Size | Size & Flags | User Data Capacity |
|---|---|---|---|
| Chunk G | 0x00000000 |
0x000000d1 |
200 bytes |
| Chunk H | 0x00000000 |
0x000000d1 |
200 bytes |
| Chunk I | 0x00000000 |
0x000001a1 |
400 bytes |
| Chunk J | 0x00000000 |
0x000000d1 |
200 bytes |
| Chunk K | 0x00000000 |
0x000000d1 |
200 bytes |
| Chunk L | 0x00000000 |
0x000000d1 |
200 bytes |
| Chunk | Chunk Address | User Pointer | Chunk Size |
|---|---|---|---|
| Chunk G | 0x5655a1a0 |
0x5655a1a8 |
0xd0 |
| Chunk H | 0x5655a270 |
0x5655a278 |
0xd0 |
| Chunk I | 0x5655a340 |
0x5655a348 |
0x1a0 |
| Chunk J | 0x5655a4e0 |
0x5655a4e8 |
0xd0 |
| Chunk K | 0x5655a5b0 |
0x5655a5b8 |
0xd0 |
| Chunk L | 0x5655a680 |
0x5655a688 |
0xd0 |
Initial state — all allocated, unsorted bin empty:
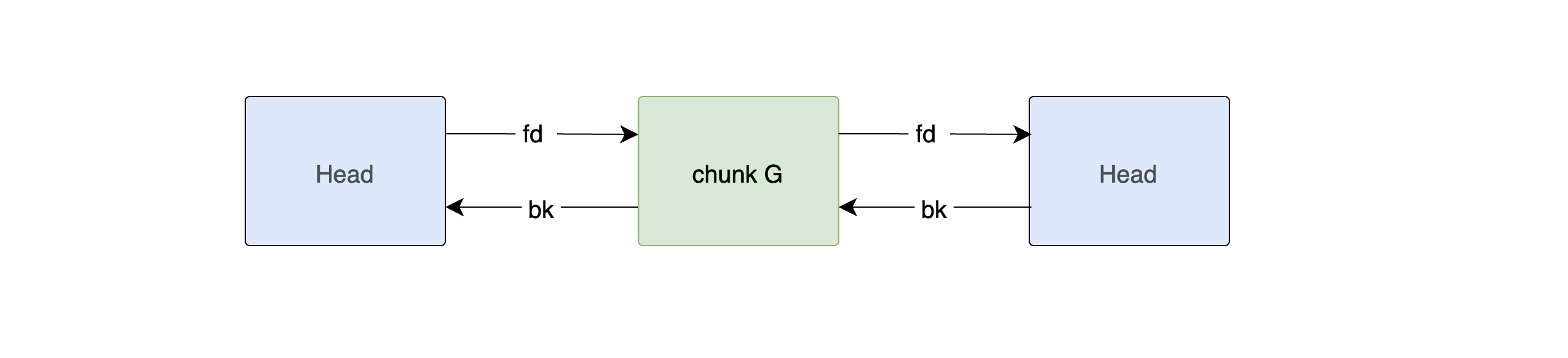
Step 1 — free(G)
G is 0xd0 bytes. There fore this is above fastbin range. No adjacent free chunks to coalesce with (H is still allocated, so P bit in H is set). G goes straight into the unsorted bin.
The allocator writes fd and bk into G's user data region. Since the bin is empty, both point to the bin head — the main_arena address 0xf7faf798.
| Chunk | Prev Size | Size & Flags | fd | bk |
|---|---|---|---|---|
| Chunk G | 0x00000000 |
0x000000d1 |
0xf7faf798 |
0xf7faf798 |
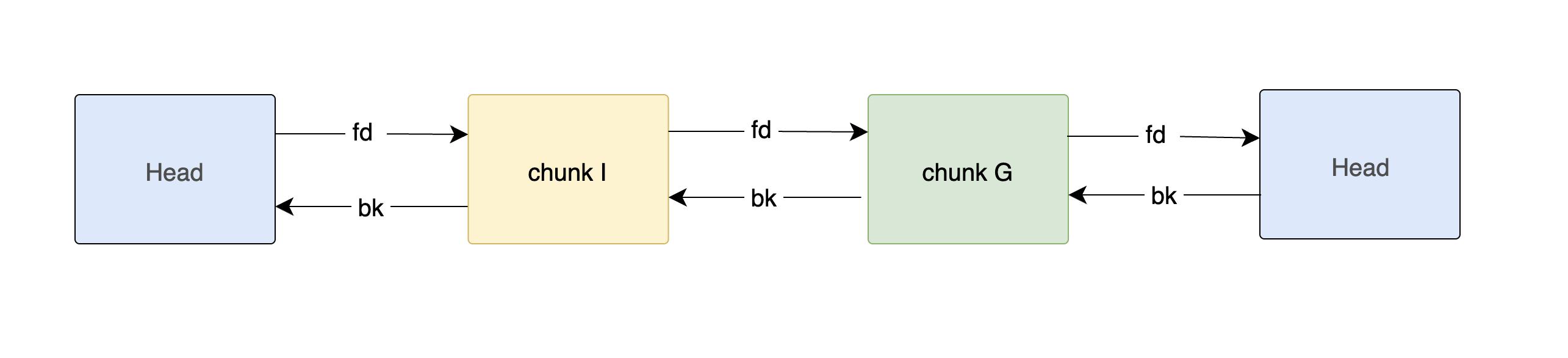
Step 2 — free(I)
You may wonder why I did not choose H :) That was intentional.
If we free H immediately after freeing G, another behavior called coalescing (consolidation) occurs because G and H are adjacent chunks.
I do not want to introduce coalescing yet and make things unnecessarily complicated. Let us first understand how the unsorted bin itself works.
Here, chunk I is 0x1a0 (400) bytes.
Its neighboring chunks H and J are still allocated, so no consolidation occurs.
glibc inserts I into the unsorted bin.
Newly freed chunks are inserted immediately after the bin head (bin->fd side)
| Chunk | Prev Size | Size & Flags | fd | bk |
|---|---|---|---|---|
| Chunk G | 0x00000000 |
0x000000d1 |
0xf7faf798 |
0x5655a340 |
| Chunk I | 0x00000000 |
0x000001a1 |
0x5655a1a0 |
0xf7faf798 |
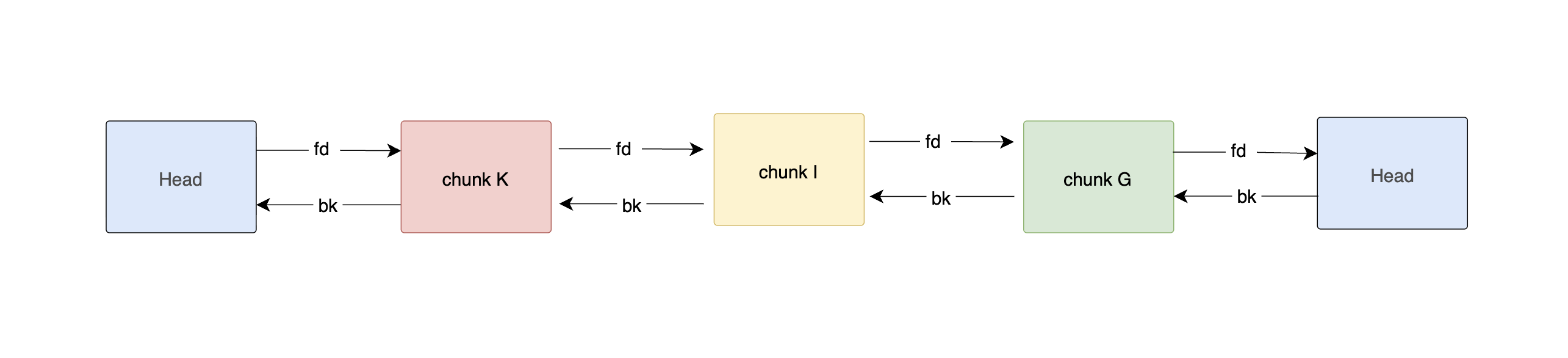
Step 3 — free(K)
K is also 0xd0 bytes.
Its neighboring chunks J and L are still allocated, so no consolidation occurs.
glibc inserts K into the unsorted bin.
The newly freed chunk is inserted at the front.
| Chunk | Prev Size | Size & Flags | fd | bk |
|---|---|---|---|---|
| Chunk G | 0x00000000 |
0x000000d1 |
0xf7faf798 |
0x5655a270 |
| Chunk I | 0x00000000 |
0x000000d1 |
0xf7faf798 |
0xf7faf798 |
| Chunk K | 0x00000000 |
0x000000d1 |
0xf7faf798 |
0xf7faf798 |
When K is inserted at the front:
- H's
fd= bin head (0xf7faf798) - H's
bk= old front = G's chunk address (0x5655a1a0) - G's
fdnow updated to H's chunk address (0x5655a270) - G's
bkstays as bin head
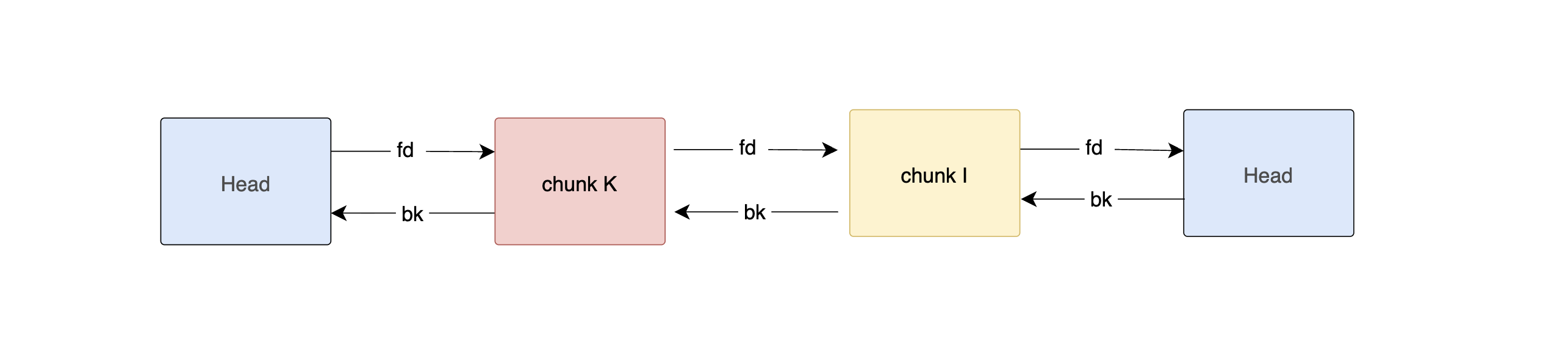
malloc() — FIFO Drain
Now, we are going to see what happens when we request some memory. Assume we call malloc(200). So we need a chunk size 0xd0.
The allocator walks from the tail of the unsorted bin — which is G (the oldest).
G is an exact match (0xd0 == 0xd0). G is unlinked and returned immediately.
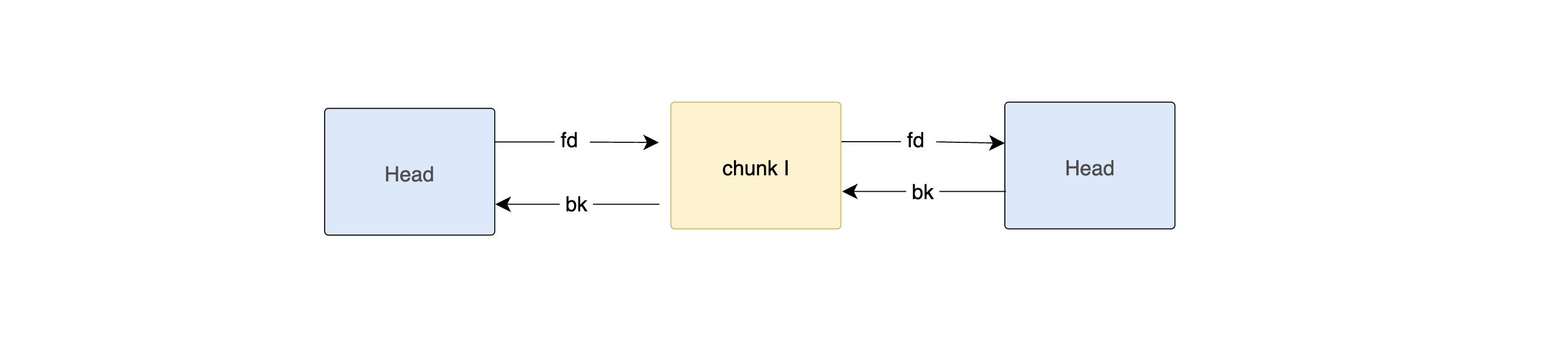
Second malloc(200) → walks from new tail (I) →
It does not match the size. There for go to K. K size is exact match. returns K.
Coalescing — What Happens When Adjacent Chunks Are Both Free
To understand this concept we need to free two chunks which are located adjusant. You may remember that just after free(G), we called free(I). I did not call free(H). At that point I mentioned that if we free two adjusent chunks there is something called Coalescing happen. At that point I did not wan to explain it.
Now lets see what happens. For that we need to consider the state where we have call free(G). So the below is the state of unsorted bins.
Let us free G, then free H (which is physically adjacent to G in memory):
free(H); // H is adjacent to GWhen free(H) is called, glibc performs two boundary checks:
-
Backward Coalescing (check previous chunk) - glibc looks at the PREV_INUSE (P) bit in H's size field. If that bit is 0, the previous chunk (G) is free. The previous chunk's size is read from H's prev_size field, and glibc walks backward in memory to find G's chunk header.
-
Forward Coalescing (check next chunk) - glibc looks at the chunk after H (chunk I) and checks I's PREV_INUSE bit. If that bit is 0, H's neighbor ahead is also free.
In our case:
G was already freed → H's PREV_INUSE bit = 0 I is still allocated → I's PREV_INUSE bit = 1
So only backward coalescing occurs here.
Before the free: ChunkPrev SizeSize & FlagsStatusChunk G0x000000000x000000d0Free (in unsorted bin)Chunk H0x000000d00x000000d1AllocatedChunk I0x000000000x000001a1Allocated When free(H) is called:
glibc sees H's PREV_INUSE = 0 → G is free G is unlinked from the unsorted bin G and H are merged into a single larger chunk The merged chunk's size = G's size + H's size = 0xd0 + 0xd0 = 0x1a0 The merged chunk starts at G's address (0x5655a1a0) The merged chunk is inserted into the unsorted bin as a fresh entry
ChunkChunk AddressSizefdbkMerged G+H0x5655a1a00x000001a00xf7faf7980xf7faf798 The merged chunk now occupies memory from 0x5655a1a0 to 0x5655a340, which is exactly where I begins. I's prev_size field is also updated to 0x1a0 and its PREV_INUSE bit is cleared to reflect that the chunk before it is now free.
Why does coalescing matter? Without it, the heap would gradually fill with small, unusable free fragments — a condition called heap fragmentation. Coalescing ensures that adjacent free memory is reunited into larger chunks that can satisfy bigger future allocations.
Small Bins
Small bins hold chunks of a specific fixed size. There are 62 small bins (indices 2–63 in the bins[] array), each dedicated to one chunk size.
On 32-bit: sizes range from 16 to 504 bytes in 8-byte steps. On 64-bit: sizes range from 32 to 1008 bytes in 16-byte steps.
Smallbin[0] (bins[2]): all chunks of size 16 (32-bit) / 32 (64-bit)
Smallbin[1] (bins[4]): all chunks of size 24 (32-bit) / 48 (64-bit)
Smallbin[2] (bins[6]): all chunks of size 32 (32-bit) / 64 (64-bit)
...
Smallbin[61] (bins[124]): all chunks of size 504 (32-bit) / 1008 (64-bit)The bin index for a chunk of size s is:
bin_index = (s >> 3) - 1 // 32-bit
bin_index = (s >> 4) - 1 // 64-bitKey properties:
- Exact fit —
malloc(24)checks only the 24-byte bin. No searching needed. - Doubly linked FIFO — chunks are inserted at the front, removed from the back. Oldest-in, first-out. This is fairer for cache behavior than LIFO.
- Circular — like the unsorted bin, each small bin is a circular list with the bin head inside
main_arena. - No coalescing on insertion — chunks are placed in small bins as-is. Coalescing happened earlier, during
free().
When malloc(n) checks the matching small bin and finds a chunk, it unlinks it from the doubly-linked list and returns it. If the bin is empty, the search continues through the unsorted bin and then large bins.
The doubly-linked structure (both fd and bk) is what makes safe unlinking possible — and what makes corrupted bk pointers useful as write-what-where primitives in exploitation. We'll return to this in the next article.
Large Bins
Large bins hold chunks that are too big for small bins. There are 63 large bins (indices 64–126 in bins[]), and each one covers a range of sizes rather than a single size. The ranges get progressively wider:
Largebin[0] (bins[128]): 512 – 568 bytes (32-bit) / 1024 – 1088 bytes (64-bit)
Largebin[1] (bins[130]): 576 – 632 bytes
Largebin[2] (bins[132]): 640 – 696 bytes
...
(ranges widen logarithmically)
...
Largebin[32] (bins[192]): 16384 – 24575 bytes
...
Largebin[62] (bins[252]): everything above ~4 MBThe first 32 bins cover 64-byte ranges; the next group covers 512-byte ranges; then 4096-byte ranges and so on. This keeps the total number of bins manageable while still giving reasonable granularity for common large sizes.
The skip list: fd_nextsize and bk_nextsize
Because each large bin holds chunks of different sizes, simply having fd/bk isn't enough for efficient lookup — you'd have to walk every chunk to find the right fit. Large bin chunks therefore carry two extra pointers in the free chunk layout:
Large free chunk:
[ prev_size | size | fd | bk | fd_nextsize | bk_nextsize | ... ]fd/bk— the standard doubly-linked list, linking all chunks in this bin in insertion orderfd_nextsize— points to the next chunk in the bin that has a different (smaller) sizebk_nextsize— points to the previous chunk in the bin that has a different (larger) size
Chunks with the same size are linked together via fd/bk, but only the first chunk of each size has non-null fd_nextsize/bk_nextsize. This forms a skip list across distinct sizes:
Largebin[0]:
600 bytes → 600 bytes → 580 bytes → 540 bytes → NULL
↑ ↑
(same-size group) fd_nextsize skips hereKey properties:
- Doubly linked — supports O(1) unlinking
- Sorted descending by size — largest chunk is at the front
- Best-fit allocation —
malloc(n)walks the skip list to find the smallest chunk that still fits, then splits it if necessary - Remainder goes back to unsorted bin — the leftover after a split is inserted at the front of the unsorted bin, not back into the large bin
When malloc(n) reaches large bins it:
- Computes the large bin index for size
n - If the bin is non-empty and its largest chunk is big enough, walks
fd_nextsizeto find the smallest chunk ≥ n (best fit) - Unlinks that chunk, splits it if it's larger than needed, puts the remainder in the unsorted bin
- If no chunk in that bin fits, checks successively larger bins until it finds one, or falls back to the top chunk
Tcache — The Modern Fast Path
Starting with glibc 2.26 (released in 2017), a new caching layer was added on top of everything we've discussed so far — the thread-local cache, or tcache. On any modern Linux distribution, tcache is the very first thing malloc() checks and the very first place free() deposits a chunk.
The motivation is performance. Fast bins were already fast, but they were part of the main arena — every access required taking the arena's mutex. In a multithreaded program that alone serializes all allocations. Tcache sidesteps the mutex entirely: each thread gets its own completely private cache. No locking. No synchronization. Just a pointer lookup.
The internal structures
Tcache is built around two C structs. Understanding them is the key to understanding everything else.
/* One entry: stored at the start of each free chunk in tcache */
typedef struct tcache_entry {
struct tcache_entry *next; /* fd: next free chunk of same size */
struct tcache_perthread_struct *key; /* added glibc 2.29 — double-free guard */
} tcache_entry;
/* One of these per thread — lives at the very start of the thread's heap */
typedef struct tcache_perthread_struct {
uint16_t counts[TCACHE_MAX_BINS]; /* how many chunks are in each bin */
tcache_entry *entries[TCACHE_MAX_BINS]; /* head pointer for each bin (LIFO stack) */
} tcache_perthread_struct;TCACHE_MAX_BINS defaults to 64. So the perthread struct holds 64 counters and 64 head pointers — one per size class.
The perthread struct itself is allocated on the heap the first time the thread calls malloc(). It sits at the very beginning of the heap region, right before any user allocations. In GDB you can find it by looking at the first chunk on the heap — it's not a user allocation, it's this bookkeeping structure.
Heap start:
[ tcache_perthread_struct ] ← ~1088 bytes, one per thread
[ user chunk A ]
[ user chunk B ]
...Size classes and bin layout
On a 64-bit system, tcache covers chunk sizes from 0x20 (32 bytes) up to 0x410 (1040 bytes), in steps of 0x10 (16 bytes). That gives exactly 64 bins:
Bin 0: chunk size 0x20 (malloc requests 0–8 bytes)
Bin 1: chunk size 0x30 (malloc requests 9–24 bytes)
Bin 2: chunk size 0x40 (malloc requests 25–40 bytes)
...
Bin 63: chunk size 0x410 (malloc requests up to ~1032 bytes)On 32-bit: chunk sizes 0x10 to 0x210, in 8-byte steps, same 64 bins.
The bin index for a requested size is:
tcache_idx = (chunk_size - 1) / (2 * SIZE_SZ) // SIZE_SZ = 8 on 64-bit, 4 on 32-bitEach bin is a singly-linked LIFO stack — only next (the fd equivalent), no bk. And each bin holds at most 7 chunks by default. The counts[] array tracks the current depth of each bin.
Thread's tcache:
counts: [3] [1] [0] [2] ...
entries: [0x20 bin] → chunk_c → chunk_b → chunk_a → NULL
[0x30 bin] → chunk_x → NULL
[0x40 bin] → NULL
[0x50 bin] → chunk_f → chunk_e → NULL
...How free() places a chunk in tcache
When free(ptr) is called, before anything else, glibc checks:
- Is the chunk size within tcache range (≤ 0x410 on 64-bit)?
- Is the matching bin not full (
counts[idx] < 7)?
If both are true, the chunk is stashed in tcache immediately:
// Simplified from glibc malloc/malloc.c
tcache_entry *e = (tcache_entry *) chunk2mem(chunk);
e->key = tcache; // write perthread struct ptr (double-free guard)
e->next = tcache->entries[tc_idx]; // push: new head points to old head
tcache->entries[tc_idx] = e; // update head
tcache->counts[tc_idx]++; // increment counterThat's it. No coalescing. No PREV_INUSE manipulation. No lock. The chunk is pushed onto the front of the singly-linked list in a handful of instructions.
If the bin is already full (count == 7), the chunk falls through to the normal free() path — fast bins, unsorted bin, coalescing.
How malloc() retrieves a chunk from tcache
On malloc(n), tcache is checked before anything else:
// Simplified
size_t tc_idx = csize2tidx(checked_request2size(n));
if (tc_idx < TCACHE_MAX_BINS && tcache->counts[tc_idx] > 0) {
tcache_entry *e = tcache->entries[tc_idx]; // pop from head
tcache->entries[tc_idx] = e->next;
tcache->counts[tc_idx]--;
return chunk2mem(e); // return user pointer
}
// … fall through to arenaPop the head, return it. No size validation (historically). No alignment check. Just a pointer. This is as fast as a allocator can get.
Tcache fill — batch loading from other bins
When malloc(n) misses tcache but finds chunks in the fast bin or unsorted bin, glibc doesn't just return one chunk. It fills the tcache first, then returns one. For fast bins specifically:
fast bin has 5 chunks of the right size
tcache has 0 chunks for that size
→ glibc moves up to min(5, 7) = 5 chunks into tcache, then pops and returns one
→ next 4 malloc() calls of the same size hit tcache directlyThis batch fill amortizes the cost of accessing the arena-locked fast bin across multiple future allocations. It's a prefetch strategy: pay the lock cost once, get several lock-free allocations in return.
The same fill behavior happens when walking the unsorted bin — any chunk of matching size that gets sorted during a malloc() walk is placed into tcache rather than the small bin, up to the 7-chunk limit.
The key field — double-free detection (glibc 2.29+)
Early tcache (glibc 2.26–2.28) had no double-free detection at all. free(ptr); free(ptr); would silently create a loop in the singly-linked list, and the next two malloc() calls of the same size would both return the same chunk — a trivial exploitation primitive.
glibc 2.29 added the key field to close this gap. When a chunk is inserted into tcache, glibc writes a pointer to the current thread's tcache_perthread_struct into the chunk's key field (which occupies the bk-equivalent slot of the free chunk). On the next free(ptr) call, glibc checks:
if (e->key == tcache) {
// Possible double-free — scan the bin to confirm
tcache_entry *tmp = tcache->entries[tc_idx];
while (tmp) {
if (tmp == e) malloc_printerr("free(): double free detected in tcache 2");
tmp = tmp->next;
}
}The scan is O(n) in the bin depth, but since the bin holds at most 7 entries the cost is bounded. It catches the obvious double-free. Note that it only fires if the chunk is still in tcache when freed again — if the chunk was popped by a malloc() in between, the key field gets overwritten by user data and the check doesn't trigger.
Pointer mangling — PROTECT_PTR (glibc 2.32+)
glibc 2.32 added a second hardening: the next pointer stored in tcache entries (and fast bin fd pointers) is now obfuscated using a simple XOR scheme called PROTECT_PTR:
#define PROTECT_PTR(pos, ptr) \
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
#define REVEAL_PTR(ptr) \
PROTECT_PTR (&ptr, ptr)When storing a next pointer at address pos, glibc XORs it with pos >> 12 (the page number of the storage location). To read it back, it reverses the XOR. The "secret" is the page address of the chunk itself — an attacker can't forge a useful next pointer without knowing where the tcache entry lives in memory.
Before glibc 2.32, overwriting a freed chunk's next with an arbitrary address was enough to make the next malloc() return that address. With pointer mangling, the attacker also needs a heap address leak to compute the correct obfuscated value:
stored_next = (heap_chunk_addr >> 12) XOR target_addressWithout that leak, a naively written fake next pointer decodes to garbage and the allocation returns an invalid address — usually crashing before it's useful.
The full picture: free() decision tree
free(ptr)
│
├─ Is size in tcache range AND bin not full?
│ YES → push to tcache. Done. ← the common case, no lock
│
├─ Is chunk mmap'd (IS_MMAPPED bit set)?
│ YES → munmap(). Done.
│
├─ Is size in fast bin range?
│ YES → push to fast bin. Done. ← still no coalescing
│
└─ Otherwise (large chunk, or fast bin range but arena consolidation triggered)
→ try backward coalesce (check PREV_INUSE of this chunk)
→ try forward coalesce (check PREV_INUSE of next-next chunk)
→ place result in unsorted bin
→ if adjacent to top chunk, merge into wildernessThe full picture: malloc() decision tree
malloc(n)
│
├─ 1. tcache hit?
│ YES → pop and return. ← the common case
│
├─ 2. n > mmap threshold (~128KB)?
│ YES → mmap() a fresh region, return it
│
├─ 3. Fast bin hit?
│ YES → pop chunk, fill tcache with remaining fast bin chunks, return
│
├─ 4. Small bin exact match?
│ YES → unlink from doubly-linked bin, return
│
├─ 5. Walk unsorted bin
│ exact match → return it (possibly after filling tcache)
│ otherwise → sort each chunk into its small or large bin as we walk
│
├─ 6. Large bin best-fit
│ find smallest chunk ≥ n via fd_nextsize skip list
│ split if necessary, put remainder in unsorted bin, return
│
├─ 7. Larger bins (check successively bigger large bins)
│
└─ 8. Top chunk (wilderness) — carve off the front
if top chunk too small → sbrk() / mmap() to extend it, then carveThe Top Chunk (Wilderness)
At the very end of the heap sits a special chunk called the top chunk, also known affectionately as the wilderness. It represents all the unallocated memory at the top of the heap region — everything the program has requested from the OS but not yet carved up into smaller chunks.
You've already seen the top chunk in action in the GDB examples earlier. Remember this line?
0x5655a1b8: 0x00000000 0x00021e49 0x00000000 0x00000000That 0x00021e49 is the top chunk's size field. It's huge (about 138 KB) because it's essentially "the rest of the heap." Each time a malloc() call can't find a suitable chunk in any bin, the allocator falls back to the top chunk it carves a new chunk off the front of the wilderness and shrinks the top chunk by that amount. That's why, between each malloc() in our earlier example, we saw the top chunk's size shrink from 0x21e49 → 0x21e39 → 0x21e29.
The top chunk has a few special properties:
- It's never in any bin. The allocator keeps a direct pointer to it in the arena structure (
av->top). - It has no neighbor to its right. Its PREV_INUSE bit is conceptually always set, and its "next chunk" doesn't exist — attempting to read it would walk off the end of the heap.
- It absorbs adjacent frees. When you free a chunk that sits immediately before the top chunk, it doesn't go into a bin — it's merged directly into the wilderness. We saw this at the end of the earlier example, when freeing chunk C caused the top chunk to jump backward and swallow both B and C.
- It grows the heap when exhausted. If the top chunk is too small to satisfy a request, the allocator calls
sbrk()(for the main heap) ormmap()(for very large requests or secondary arenas) to extend it. - It can shrink. If the top chunk grows beyond
M_TRIM_THRESHOLD(default 128 KB), glibc trims the excess back to the OS with a negativesbrk(). This is exactly the "heap trimming" we observed at the very end of the GDB walkthrough, where0x21e49became0x20e49after glibc returned a 4 KB page to the kernel.
From an attacker's perspective, the top chunk is interesting because its size field is just another 8-byte value sitting in memory. If a heap buffer overflow lets you overwrite it, you can forge a gigantic size, and then request a huge malloc() that makes the allocator's internal pointer "wrap around" to an arbitrary address. This is the classic House of Force technique. Again — a story for the next article.
The Arena
Finally, the wrapper that ties all of this together: the arena. An arena is glibc's internal bookkeeping structure for a heap. It holds every piece of state we've discussed so far — all the bins, the top chunk pointer, a lock, and references to the underlying memory regions.
Here's a simplified view of struct malloc_state (the arena):
struct malloc_state {
mutex_t mutex; // Lock for thread safety
int flags;
mfastbinptr fastbinsY[10]; // Fast bins
mchunkptr top; // The top chunk
mchunkptr last_remainder; // Last split remainder
mchunkptr bins[254]; // Unsorted + small + large bins
unsigned int binmap[4]; // Bitmap of non-empty bins
struct malloc_state *next; // Linked list of arenas
...
};Every Linux process has at least one arena: the main arena, which lives as a static global inside libc itself. That's why, in our earlier GDB session, chunk B's fd and bk pointers after free(b) both pointed to 0xf7faf798 — a fixed address inside libc.so. That's the main arena's unsorted bin head.
Why multiple arenas?
In a single-threaded program, the main arena is all you ever need. But in a multithreaded program, every malloc() and free() would need to take the arena lock, serializing every thread on a single mutex. That would kill performance.
So glibc creates additional arenas on demand. When a thread calls malloc() and finds the main arena locked, glibc may spin up a new arena (up to 8 * number_of_cores by default) and assign that thread to it. Each extra arena has its own heap region, allocated via mmap() rather than sbrk(), and its own independent set of bins.
Main arena → sbrk() heap (thread 1)
Arena 2 → mmap'd region (thread 2)
Arena 3 → mmap'd region (thread 3)
...This is exactly what the NON_MAIN_ARENA flag (bit 2 of the size field, the A bit) is for. When free() sees a chunk with A = 1, it knows the chunk didn't come from the main arena and has to walk back to that chunk's own arena header to put the chunk in the right bin. glibc finds the arena header by masking the chunk's address down to a heap-aligned boundary and reading a small "heap_info" struct at the start of the mmap'd region.
Thread-local state
On top of arenas, each thread also carries two pieces of thread-local state:
- The tcache — its private fast-path cache (discussed above).
- An "arena hint" — the last arena this thread used, so it can reuse it without searching.
Put all of this together and the full hierarchy looks like this:
Thread 1:
tcache (private)
│
▼
Main arena (shared, locked)
│
├── fastbins[10]
├── bins[254] (unsorted, small, large)
├── top chunk → sbrk() heap
└── next → Arena 2
│
├── fastbins[10]
├── bins[254]
├── top chunk → mmap'd heap
└── next → ...Every malloc() drills down through this structure: tcache first, then fastbins, then small/large bins, then top chunk, then sbrk/mmap. Every free() does the reverse, depositing chunks into whichever layer accepts them.
That is the full picture of glibc's malloc. Chunks wrapped in headers, organized into bins, grouped under arenas, cached per-thread, all stitched together with pointer metadata stored inside the free memory itself. And that last detail — metadata living inside the very memory the program is free to overwrite — is the crack through which every heap exploit in the next article will squeeze.






